|
АЛГОРИТМ FOREL
Задача таксономии заключается в разделении
множества объектов на заданное количество групп (таксонов, кластеров) с заранее
неизвестными параметрами по заданному критерию.
Разбиение одного
и того же множества объектов на таксоны может различаться, поэтому для
определения наилучшего разбиения вводится критерий качества таксономии.
Введем
обозначения:
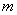 - количество объектов
в множестве, которое необходимо разделить на группы; - количество объектов
в множестве, которое необходимо разделить на группы;
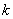 - количество таксонов ( - количество таксонов (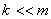 ); );
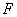 - критерий качества
таксономии. - критерий качества
таксономии.
Алгоритмы таксономии класса FOREL используют
критерий , основанный на гипотезе компактности: в один таксон должны собираться
объекты, "похожие" по своим свойствам на некоторый „центральный”
объект, то есть объекты близкие по своим характеристикам
должны попасть в один таксон. В результате получаются таксоны сферической
формы.
Пусть
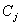 - координаты центра - координаты центра 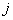 -го таксона, -го таксона,
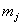 - количество объектов
в -ом таксоне, - количество объектов
в -ом таксоне,
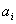 , , 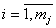 - объекты -го таксона, - объекты -го таксона,
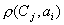 - расстояние между
центром и - расстояние между
центром и 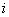 -м элементом -го таксона, -м элементом -го таксона,
тогда сумма расстояний от всех
элементов до центра -го таксона равна
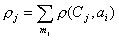 . .
Сумма внутренних расстояний для всех таксонов:
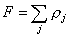 . .
Смысл критерия
состоит в том, что нужно найти такое разбиение объектов на таксонов, чтобы приведенная выше величина была минимальной. Выполнение этого условия достигается с помощью алгоритма FOREL. Опишем базовую версию и некоторые
модификации этого алгоритма.
Алгоритм FOREL. Таксоны, получаемые по этому алгоритму,
имеют сферическую форму. Количество таксонов зависит от радиуса сфер: чем
меньше радиус, тем больше получается таксонов. Вначале признаки объектов
нормируются так, чтобы значения всех признаков находились в диапазоне от нуля
до единицы. Затем строится гиперсфера минимального радиуса 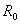 , которая охватывает все точек (все объекты
входят в один таксон). Далее радиус сфер постепенно уменьшается. Задаем радиус , которая охватывает все точек (все объекты
входят в один таксон). Далее радиус сфер постепенно уменьшается. Задаем радиус 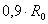 и помещаем центр сферы
в любую из имеющихся точек. Находим точки, расстояние до которых меньше
радиуса, и вычисляем координаты центра тяжести этих «внутренних» точек.
Переносим центр сферы в этот центр тяжести и снова находим внутренние точки. Сфера как бы плывет в сторону локального сгущения точек. Такая процедура
определения внутренних точек
и переноса центра сферы продолжается до тех пор, пока сфера не остановится, т. е. пока на
очередном шаге мы не обнаружим,
что состав внутренних точек, а, следовательно, и их центр тяжести, не меняется. Это означает, что
сфера остановилась в области
локального максимума плотности точек в признаковом пространстве. и помещаем центр сферы
в любую из имеющихся точек. Находим точки, расстояние до которых меньше
радиуса, и вычисляем координаты центра тяжести этих «внутренних» точек.
Переносим центр сферы в этот центр тяжести и снова находим внутренние точки. Сфера как бы плывет в сторону локального сгущения точек. Такая процедура
определения внутренних точек
и переноса центра сферы продолжается до тех пор, пока сфера не остановится, т. е. пока на
очередном шаге мы не обнаружим,
что состав внутренних точек, а, следовательно, и их центр тяжести, не меняется. Это означает, что
сфера остановилась в области
локального максимума плотности точек в признаковом пространстве.
Точки, оказавшиеся внутри
остановившейся сферы, мы объявляем принадлежащими таксону номер 1 и исключаем их из дальнейшего рассмотрения. Для оставшихся
точек описанная выше процедура повторяется до тех пор, пока все точки не
окажутся включенными в
таксоны.
Доказана сходимость алгоритма за конечное число шагов, однако легко
видеть, что решение может быть
не единственным. Так, на рис. 1 видно, что результат таксономии зависит от
того, с какой первой точки был начат процесс
|

