

|
МОДЕЛИРОВАНИЕ ДАННЫХ ПРИ ПОМОЩИ КРИВЫХ
ДЛЯ ВОССТАНОВЛЕНИЯ ПРОБЕЛОВ В ТАБЛИЦАХ |
|
МОДЕЛИРОВАНИЕ ДАННЫХ ПРИ ПОМОЩИ КРИВЫХ
ДЛЯ ВОССТАНОВЛЕНИЯ ПРОБЕЛОВ В ТАБЛИЦАХ Часть 1. Пусть задана прямоугольная таблица Необходимо
решить следующие задачи: 1. Наиболее точно определить значения пропущенных данных. 2. При необходимости так изменить данные в таблице, чтобы
они наилучшим образом соответствовали моделям, используемым для восстановления
пропусков в таблице. 3. Построить алгоритм для обработки новых строк с
пропусками, при условии что новые данные соответствуют тем же зависимостям, что
и в таблице. Для
решения этих задач предлагается использовать метод последовательного
приближения множества векторов данных прямыми вида Процедура нахождения матрицы приближения. 1.
Необходимо
минимизировать функционал
2. При фиксированных векторах yj и bj
значения xi,
доставляющие минимум форме (1), определяются из равенств ¶F/¶xi=0
следующим образом:
Начальные значения: y – нормированное на 1 случайное значение, т.е. bj – среднее
значение в столбце, т. е. 3. По фиксированному xi,
можно сразу по явным формулам посчитать значения yj и bj,
доставляющие минимум форме (1). Они определяются из двух равенств ¶F/¶yj=0 и ¶F/¶bj=0 следующим образом: Для каждого j имеем
систему из двух уравнений относительно yj и bj:
Выражая
из первого уравнения bj и подставляя полученное значение во второе, получим:
4.
Критерий
остановки – Алгоритм решения задачи. 1. Пусть 2.
По (2) и (5)
находим значения векторов 3. Рассчитываем матрицу 4.
По (1) вычисляем
значение 5.
Если 6. Иначе вычисляем В результате работы данного алгоритма происходит последовательное
исчерпание матрицы Таким образом, матрица 1.
Значения пропущенных данных определяются из значений соответствующих элементов матрицы
2. Для исправления исходной
таблицы ее заменяют матрицей 3.
Опишем операцию восстановления данных в поступающей на обработку строке aj с пробелами (некоторые
……………..
Тогда для
Если пробелы отсутствуют, то описанный метод приводит
к обычным главным компонентам исходной таблицы данных. В этом случае, начиная с Также следует учесть, что при отсутствии пробелов,
полученные прямые будут ортогональны, то есть получим ортогональную систему
факторов (прямых). Исходя из этого, при неполных данных возможен процесс
ортогонализации полученной системы факторов, который заключается в том, что
исходная таблица восстанавливается при помощи полученной системы, после чего
эта система пересчитывается заново, но уже на полных данных. (Материал заимствован из статьи А.А.Россиева.) |
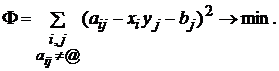
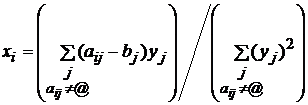 .
.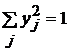 ;
;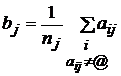 , где
, где 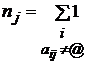 .
.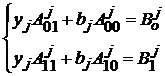 , где
, где 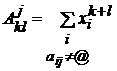 ,
, 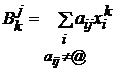 ,
,  ,
, 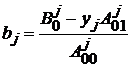 .
.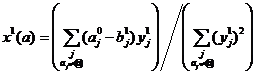 ;
;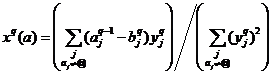 ;
;| РЕКЛАМА: |